Index
- 1. Coleta de Dados
- 2. Pré-processamento
- 3. Trasnfer Learning com Xception
- 4. Fine Tuning
- 5. Avaliando o Modelo
Sobre o Projeto.
- O dataset contém uma série de imagens de 4 tipos de grãos de café: dark, green, light e medium.
- Estarei utilizando o modelo pré treinado do keras chamado Xception, cujo tem apresentado uma acurácia geral de 94.5% na classificação de imagens e uma quantidade de parâmetros relativamente pequena(22.9M).
Coleta de Dados
Configurando a API do Kaggle para a extração do dataset.
#hide
%%writefile kaggle.json
{"username":"your_username","key":"your_API_key"} # credenciais pessoais do Kaggle
Overwriting kaggle.json
Instalando as dependências do Kaggle
#hide
!pip install -q -U kaggle
!pip install --upgrade --force-reinstall --no-deps kaggle
!mkdir ~/.kaggle
!cp kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting kaggle
Using cached kaggle-1.5.12-py3-none-any.whl
Installing collected packages: kaggle
Attempting uninstall: kaggle
Found existing installation: kaggle 1.5.12
Uninstalling kaggle-1.5.12:
Successfully uninstalled kaggle-1.5.12
Successfully installed kaggle-1.5.12
mkdir: cannot create directory ‘/root/.kaggle’: File exists
Fazendo o download do dataset pela API do Kaggle.
#getting the dataset
!kaggle datasets download -d gpiosenka/coffee-bean-dataset-resized-224-x-224
coffee-bean-dataset-resized-224-x-224.zip: Skipping, found more recently modified local copy (use --force to force download)
Importando dependências necessárias.
import os
import pandas as pd
from shutil import move
import pathlib
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import numpy as np
import random
import itertools
import zipfile
from keras_preprocessing.image import ImageDataGenerator
import tensorflow as tf
import tensorflow_hub as hub
from tensorflow.keras.preprocessing import image
Armazenando o dataset em uma pasta.
if not os.path.exists(os.path.join('/content', 'coffee_dataset')):
os.mkdir(os.path.join('/content', 'coffee_dataset'))
with zipfile.ZipFile('/content/coffee-bean-dataset-resized-224-x-224.zip', 'r') as zip_ref:
zip_ref.extractall('/content/coffee_dataset')
print('Done extracting')
Done extracting
coffee_catalog = pd.read_csv('/content/coffee_dataset/Coffee Bean.csv')
coffee_catalog
Pre-processamento
#coffee Dark Green Light Medium
dark_test = os.listdir('/content/coffee_dataset/test/Dark')
green_test = os.listdir('/content/coffee_dataset/test/Green')
light_test = os.listdir('/content/coffee_dataset/test/Light')
medium_test = os.listdir('/content/coffee_dataset/test/Medium')
print(f'Dark test coffee: {len(dark_test)} \nGreen test coffee: {len(green_test)} \nLight test coffee: {len(light_test)} \nMedium train coffee: {len(medium_test)}')
#training folder check
dark_train = os.listdir('/content/coffee_dataset/train/Dark')
green_train = os.listdir('/content/coffee_dataset/train/Green')
light_train = os.listdir('/content/coffee_dataset/train/Light')
medium_train = os.listdir('/content/coffee_dataset/train/Medium')
print(f'\nDark train coffee: {len(dark_train)} \nGreen train coffee: {len(green_train)} \nLight train coffee: {len(light_train)} \nMedium train coffee: {len(medium_train)}')
Dark test coffee: 100
Green test coffee: 100
Light test coffee: 100
Medium train coffee: 100
Dark train coffee: 300
Green train coffee: 300
Light train coffee: 300
Medium train coffee: 300
Criando uma pasta para armazenar imagens para validação do modelo.
- Dados de validação são usados para verificar a estabilidade do modelo.
- Funcionam como uma espécie de garantia de que o modelo tenha captado a maioria dos padrões dos dados.
- Evita a captação de ruídos (variância e viés baixos).
#creating a validation folder
if not os.path.exists(os.path.join('/content/coffee_dataset', 'validation')):
os.mkdir(os.path.join('/content/coffee_dataset', 'validation'))
os.mkdir(os.path.join('/content/coffee_dataset/validation', 'Dark'))#Dark
os.mkdir(os.path.join('/content/coffee_dataset/validation', 'Green'))#Green
os.mkdir(os.path.join('/content/coffee_dataset/validation', 'Light'))#Light
os.mkdir(os.path.join('/content/coffee_dataset/validation', 'Medium'))#Medium
Armazenando o caminho de cada pasta de validação.
train_path = '/content/coffee_dataset/train'
val_dark = '/content/coffee_dataset/validation/Dark'
val_green = '/content/coffee_dataset/validation/Green'
val_light = '/content/coffee_dataset/validation/Light'
val_medium = '/content/coffee_dataset/validation/Medium'
#function to move files to validation folder
def moveFiles(walk_path, path_to, name, batch_file):
counter = 0
if len(os.listdir(path_to)) == 0: #recently added
for root, subfolder, filename in os.walk(walk_path):
for files in filename:
if files.lower().startswith(name) and counter < batch_file:
path_from = os.path.join(root ,files)
move(path_from, path_to)
counter += 1
print(f'Done! moved {counter} from {path_from} to {path_to}')
else:
return 'Folder has already files in inside'
moveFiles(train_path, val_dark, 'dark', 30)
moveFiles(train_path, val_green, 'green', 30)
moveFiles(train_path, val_light, 'light', 30)
moveFiles(train_path, val_medium, 'medium', 30)
'Folder has already files in inside'
Já que o dataset não contém um conjunto de validação, criei a função moveFiles() para fazer exatamente isso. Ela move uma determinada quantidade de dados do conjunto de treino, neste caso 30 imagens de cada tipo de grão de café para o cojnunto de dados de validação.
Agora com os 3 conjuntos devidamente separados(train, test, validation), podemos prosseguir com a etapa de pre-processamento das imagens.
train_path = '/content/coffee_dataset/train'
test_path = '/content/coffee_dataset/test'
validation_path = '/content/coffee_dataset/validation'
Data Augmentation(Aumento de Dados)
- A etapa de aumento de dados é utilizada para aumentar a diversidade e quantidade dos dados do dataset.
- Muitas vezes, coletar milhões de imagens pra resolver um determinado problema pode ser um processo custoso, inviável e demorado. Para isso, recorremos a este método.
- No processo de Data Augmentation é realizado vários processos de tratamento de imagens como: Rotação da imagem, orientação da imagem, ampliação, recorte, flipping(vertical e horizontal), etc.
- No bloco de código abaixo, farei alguns dos processos de tratamento citados acima.
size = (224, 224)
batch_size = 30
# for data augmentation
train_datagen = ImageDataGenerator(rescale = 1.0/255, # redução de dimensionalidade
rotation_range = 60, # rotação
shear_range = 0.2, # distorção da imagem
zoom_range = 0.2, # ampliação
horizontal_flip = True, # flipping
fill_mode = 'nearest' # preenchimento
)
train_generator = train_datagen.flow_from_directory(
train_path,
target_size = (224, 224),
batch_size = batch_size,
color_mode = 'rgb',
class_mode = 'categorical'
)
test_generator = train_datagen.flow_from_directory(
test_path,
target_size = (224, 224),
batch_size = batch_size,
color_mode = 'rgb',
class_mode = 'categorical',
shuffle = False
)
validation_generator = train_datagen.flow_from_directory(
validation_path,
target_size = (224,224),
color_mode = 'rgb',
batch_size = batch_size,
class_mode = 'categorical',
shuffle = False
)
Found 1200 images belonging to 4 classes.
Found 400 images belonging to 4 classes.
Found 120 images belonging to 4 classes.
Explicação:
- train_datagen é a instância criada do método ImageDataGenerator do TensorFlow que será responsável por realizar os processos de aumento de dados(amplicação, rotação, etc) nas imagens.
- Como o nome sugere, train_generator, test_generator, validation_generator aplicam o processo de aumento de dados instanciado em train_datagen nos conjuntos de treino, teste e validação.
- O modelo Xception trabalha melhor com imagens de dimensão 224x224, então redimensionei todas as imagens de treino, teste e validação.
- batch_size corresponde a porção de elementos que ele seleciona por vez para aplicar o tratamento das imagens.
- shuffle=False são específicas para o treino e validação, uma vez que ambos não serão utilizados no treinamento, não há necessidade de aleatoriedade. Já no treino, a aleatoriedade é necessária de forma a evitar vieses e consequentemente o overfitting.
Verificando as Imagens
Imagens antes do Data Augmentation!
def show_images(folder_path, samples = 5, figsize = (30, 5)):
folder_names = os.listdir(folder_path)
#iterando entre as pastas
for folder_name in folder_names:
images_path = f'{folder_path}/{folder_name}'
# criando subplots
fig, ax = plt.subplots(1, samples, figsize = figsize)
plt.suptitle("Coffee beans belong to " + folder_name, color = 'crimson', fontsize = 20)
# Percorrendo as pastas e exibindo o número de amostras
for image_num in range(samples):
# Selecionando uma imagem aleatória
random_image_name = random.choice(os.listdir(images_path))
# Retorna uma matriz das imagens contendo os valores dos pixels.
image_matrix = plt.imread(images_path + '/' + random_image_name)
# transformando a matriz de pixels em imagem
ax[image_num].imshow(image_matrix)
# exibindo o tipo de grão de café selecionado.
ax[image_num].set_title(random_image_name)
# amostras do conjuto de treino
show_images(train_path, 7, figsize = (30,5))
Grãos de café do tipo "green".

Grãos de café do tipo "light".

Grãos de café do tipo "dark".

Grãos de café do tipo "medium".

#samples from test folders
show_images(test_path, 7, figsize = (30,5))
Grãos de café do tipo “green”

Grãos de café do tipo “light”

Grãos de café do tipo “dark”

Grãos de café do tipo “medium”

#samples from validation folders
show_images(validation_path, 7, figsize = (30,5))
Grãos de café do tipo “green”

Grãos de café do tipo “light”

Grãos de café do tipo “dark”

Grãos de café do tipo “medium”

Amostras Após o Data Augmentation!
def data_transformation_images(folder_path, image_gen_object, no_of_samples = 5, figsize = (35, 5)):
# Nome das pastas armazenados aqui
folder_names = os.listdir(folder_path)
# Iterando em cada pasta
for folder_name in folder_names:
images_path = folder_path + '/' + folder_name
# Criando subplots para as imagens
fig, ax = plt.subplots(1, no_of_samples, figsize = figsize)
# Coletando amostras
random_image_name = random.choice(os.listdir(folder_path + '/' + folder_name))
random_image = plt.imread(folder_path + '/' + folder_name + '/' + random_image_name)
plt.suptitle("Coffee beans belong to " + folder_name + '-> ' + 'Selected image: ' + random_image_name, color = 'crimson', fontsize = 20)
# Transformando em imagens e exibindo
for image_num in range(no_of_samples):
ax[image_num].imshow(train_datagen.random_transform(random_image))
ax[image_num].set_title('Transformation Number: {}'.format(image_num + 1))
data_transformation_images(train_path, train_datagen, no_of_samples = 10)




Transfer Learning com Xception
Como Utilizar o Transfer Learning?
- O transfer learning éo processo de reutilizar os pesos(weights) de um modelo pré-treinado para relizar uma tarefa semelhante.
- É comumente utilizada quando fica difícil aumentar a acuracidade da classificação devida a baixa quantidade de imagens de treino.
- É importante especificar, que neste processo de transfer learning, estarei utilizando da técnica de Extrator de Atributos Integrados, onde as camadas do modelo pré treinado são 'congeladas' durante o treino e somente as novas camadas criadas unicamente pra a classificação dos grãos de café serão treinadas para resolver o problema.
- O congelameno é necessário para as camadas NÃO treinarem novamente, caso contrário, todos os pesos do modelo ja treinado serão modificados e alterados novamente.
input_shape = (224, 224, 3)
base_model = tf.keras.applications.Xception(include_top = False) # importando o Xception
base_model.trainable = False # congelamento das camadas
#estrutura do modelo
inputs = tf.keras.Input(shape = input_shape) # tamando e dimensões das imagens
x = base_model(inputs, training = False)
x = tf.keras.layers.GlobalAveragePooling2D()(x)
outputs = tf.keras.layers.Dense(4, activation = 'softmax')(x) # output layer com 4 saidas (green, light, dark ou medium)
xception = tf.keras.Model(inputs, outputs)
xception.summary()
Model: "model_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_8 (InputLayer) [(None, 224, 224, 3)] 0
xception (Functional) (None, None, None, 2048) 20861480
global_average_pooling2d_3 (None, 2048) 0
(GlobalAveragePooling2D)
dense_3 (Dense) (None, 4) 8196
=================================================================
Total params: 20,869,676
Trainable params: 8,196
Non-trainable params: 20,861,480
_________________________________________________________________
Entendendo o Transfer Learning
- No resumo do modelo, temos uma visualização melhor da importância do transfer learning.
- Verificamos que o modelo possui mais de 20 milhões de parâmetros, mas apenas 8,196 será treinado.
- Isso ocorre devido ao congelamento das camadas, desta forma, obtemos os pesos de um modelo treinado com muito robustez de maneira instantânea, imaginem quanto poder de processamento e tempo levaria pra treinar mais de 20 milhões de parâmetros do zero.
- A única camada que será treinada é a camada de saída, sendo esta sendo uma camada especial e necessária responsável por delimitar o número de classificações que desejamos(4 saídas neste caso).
xception.compile(
optimizer = 'Adam',
loss = 'categorical_crossentropy',
metrics = ['accuracy']
)
Aqui, foi definido o tipo de otimizador "Adam", amplamente difundido entre a comunidade por ser um método realmente eficiente que utiliza pouca memória. como loss function optei pelo "Categorical Crossentropy" por sem um modelo de multiplas classificações e utilizar uma camada softmax.
callback = tf.keras.callbacks.EarlyStopping(monitor='loss', patience=3)
history = xception.fit(
train_generator,
epochs = 10,
validation_data = validation_generator,
validation_steps = validation_generator.samples // validation_generator.batch_size,
steps_per_epoch = train_generator.samples // train_generator.batch_size,
callbacks =[callback],
verbose = 1
)
Epoch 1/10
40/40 [==============================] - 21s 459ms/step - loss: 0.8138 - accuracy: 0.7275 - val_loss: 0.4601 - val_accuracy: 0.8833
Epoch 2/10
40/40 [==============================] - 17s 428ms/step - loss: 0.3606 - accuracy: 0.8975 - val_loss: 0.2851 - val_accuracy: 0.9417
Epoch 3/10
40/40 [==============================] - 17s 433ms/step - loss: 0.2548 - accuracy: 0.9367 - val_loss: 0.2327 - val_accuracy: 0.9500
Epoch 4/10
40/40 [==============================] - 17s 431ms/step - loss: 0.2141 - accuracy: 0.9475 - val_loss: 0.2043 - val_accuracy: 0.9333
Epoch 5/10
40/40 [==============================] - 17s 429ms/step - loss: 0.1891 - accuracy: 0.9475 - val_loss: 0.1940 - val_accuracy: 0.9333
Epoch 6/10
40/40 [==============================] - 17s 434ms/step - loss: 0.1643 - accuracy: 0.9567 - val_loss: 0.1795 - val_accuracy: 0.9667
Epoch 7/10
40/40 [==============================] - 18s 447ms/step - loss: 0.1476 - accuracy: 0.9550 - val_loss: 0.1601 - val_accuracy: 0.9500
Epoch 8/10
40/40 [==============================] - 17s 429ms/step - loss: 0.1354 - accuracy: 0.9608 - val_loss: 0.1604 - val_accuracy: 0.9333
Epoch 9/10
40/40 [==============================] - 17s 436ms/step - loss: 0.1233 - accuracy: 0.9617 - val_loss: 0.1058 - val_accuracy: 0.9833
Epoch 10/10
40/40 [==============================] - 17s 431ms/step - loss: 0.1205 - accuracy: 0.9700 - val_loss: 0.1328 - val_accuracy: 0.9583
- Utilizei um callback de early stopping, isto significa que ele vai parar o treinamento caso não note nenhuma melhora num periodo de 3 épocas.
- Passei o conjunto de dados de validação para monitorar o modelo a cada época e verificar seu treinamento.
- steps_per_epoch diz quantos "passos" o modelo vai realizar em uma única época. Como definimos um batch_size = 30, o modelo realizará 30 forward propagations, então a loss function será calculada em todas as 30 predições que o modelo realizou.
- Chamamos de uma época quando o modelo realizou vários "passos" e percorreu todo o conjunto de treinamento.
#evaluation
xception.evaluate(x = test_generator )
14/14 [==============================] - 5s 367ms/step - loss: 0.1190 - accuracy: 0.9725
[0.11898920685052872, 0.9725000262260437]
O modelo atingiu 97% de acurácia em 10 épocas.
Fine Tuning
- Esta etapa simplesmente consiste em fazer pequenos ajustes durante o processo de refinamento do modelo.
- Farei isso descongelando as 10 ultimas do modelo pre-treinado xception, isto quer dizer que as 10 últimas camadas não estarão mais congeladas, elas treinarão como as novas camada inseridas e em seguida, verificarei como o modelo performou.
#Set all trainable back to True
base_model.trainable = True
#making making the last 10 layers trainable
for layer in base_model.layers[:-10]:
layer.trainable = False
#checking the trainable layers, uncomment to see
#for layer in base_model.layers:
#print(layer.trainable)
#recompiling the model
xception.compile(loss = 'categorical_crossentropy', optimizer = tf.keras.optimizers.Adam(learning_rate = 0.0001), metrics = ['accuracy'])
#for layer in xception.layers:
# print(layer.name, layer.trainable)
xception.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 224, 224, 3)] 0
xception (Functional) (None, None, None, 2048) 20861480
global_average_pooling2d (G (None, 2048) 0
lobalAveragePooling2D)
dense (Dense) (None, 4) 8196
=================================================================
Total params: 20,869,676
Trainable params: 5,504,516
Non-trainable params: 15,365,160
Como podemos ver, apenas com 10 camadas liberadas para o treinamento, temos agora mais de 5 milhões de parâmetros.
#fine tune for more 15 epochs to reduce loss value
history_fine_tune = xception.fit(
train_generator,
epochs = 15,
validation_data = validation_generator,
validation_steps = validation_generator.samples // validation_generator.batch_size,
steps_per_epoch = train_generator.samples // train_generator.batch_size,
verbose = 1,
callbacks = [callback]
)
Epoch 1/15
40/40 [==============================] - 21s 461ms/step - loss: 0.1631 - accuracy: 0.9375 - val_loss: 0.0718 - val_accuracy: 0.9750
Epoch 2/15
40/40 [==============================] - 18s 437ms/step - loss: 0.0853 - accuracy: 0.9658 - val_loss: 0.0845 - val_accuracy: 0.9667
Epoch 3/15
40/40 [==============================] - 18s 452ms/step - loss: 0.0612 - accuracy: 0.9800 - val_loss: 0.0751 - val_accuracy: 0.9667
Epoch 4/15
40/40 [==============================] - 17s 434ms/step - loss: 0.0480 - accuracy: 0.9792 - val_loss: 0.0515 - val_accuracy: 0.9833
Epoch 5/15
40/40 [==============================] - 18s 436ms/step - loss: 0.0610 - accuracy: 0.9767 - val_loss: 0.1119 - val_accuracy: 0.9583
Epoch 6/15
40/40 [==============================] - 18s 441ms/step - loss: 0.0684 - accuracy: 0.9717 - val_loss: 0.0586 - val_accuracy: 0.9917
Epoch 7/15
40/40 [==============================] - 17s 433ms/step - loss: 0.0342 - accuracy: 0.9867 - val_loss: 0.0200 - val_accuracy: 1.0000
Epoch 8/15
40/40 [==============================] - 18s 437ms/step - loss: 0.0376 - accuracy: 0.9858 - val_loss: 0.0159 - val_accuracy: 1.0000
Epoch 9/15
40/40 [==============================] - 17s 432ms/step - loss: 0.0396 - accuracy: 0.9875 - val_loss: 0.0534 - val_accuracy: 0.9750
Epoch 10/15
40/40 [==============================] - 18s 450ms/step - loss: 0.0406 - accuracy: 0.9858 - val_loss: 0.0163 - val_accuracy: 0.9917
Com o fine tuning, podemos ver que a loss function diminuiu e a acurácia geral aumentou, exatamente como esperado.
Avaliando o Modelo
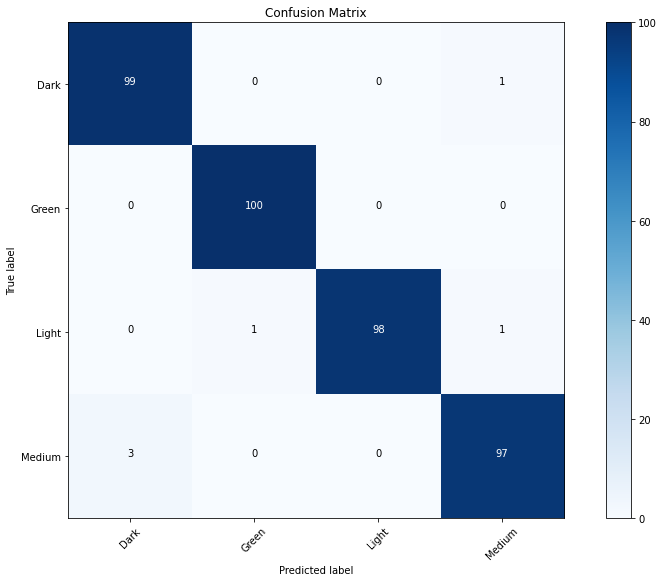
Matriz de Confusão
- Matriz de Confusão é uma métrica muito utilizada em problemas de classificação pois auxilia na avaliação de modelos de classificação, mapeando imagens que o modelo classificou corretamente(verdadeiros positivos) e as que ele classificou de maneira equivocada(falso positivo), o mesmo serve para o caso oposto(verdadeiro negativo, falso negativo).
- Desta forma, podemos verificar se possui algum caso específico em que o modelo esteja errando bastante como por exemplo, grande parte dos erros poderia ser em apenas um caso em que o modelo precisaria classificar grãos de café do tipo 'dark'.
#Confusion Matrix Function
def get_CM(cm, classes, normalize = False, title = 'Confusion Matrix', cmap = plt.cm.Blues):
plt.figure(figsize=(12,8))
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print("Normalized confusion matrix")
else:
print('Confusion matrix, without normalization')
print(cm)
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
predictions = xception.predict(x = test_generator, steps = len(test_generator), verbose = 0)
cm = confusion_matrix(y_true = test_generator.classes, y_pred = predictions.argmax(axis = 1))
cm_plot_labels = ['Dark','Green','Light','Medium']
get_CM(cm = cm, classes = cm_plot_labels, title = 'Confusion Matrix')
Confusion matrix, without normalization
[[ 99 0 0 1]
[ 0 100 0 0]
[ 0 1 98 1]
[ 3 0 0 97]]
train_generator.batch_size
train_generator.samples
train_generator.class_indices
{'Dark': 0, 'Green': 1, 'Light': 2, 'Medium': 3}
Gráfico de uma Função de Erro
losses = pd.DataFrame(history.history)
losses[['loss', 'val_loss']].plot(figsize = (15,8))
plt.show()
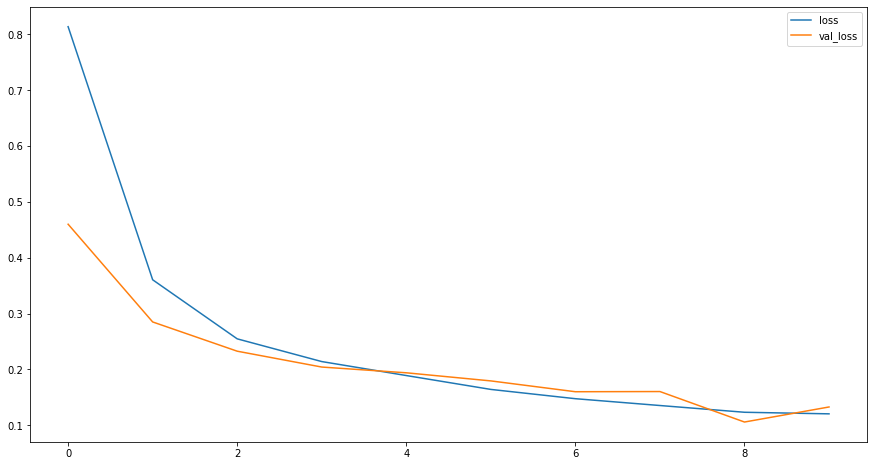
- Função de erro: Uma função de erro serve para avaliar a predição do modelo. Se houver exemplos conhecidos, uma função de erro poderá fazer uma comparação para avaliar a precisão do modelo.
- Quanto menor for o valor da função de erro, melhor o modelo performará.
- Como podemos ver, a medida em que as épocas aumentam, a função de erro diminui, o que é esperado que aconteça.
Gráfico de Acurácia
losses[['accuracy', 'val_accuracy']].plot(figsize = (15, 8))
plt.axhline(0.90, color = 'green', linestyle = '--')
plt.axvline(5, color = 'green', linestyle = '--')
plt.show()
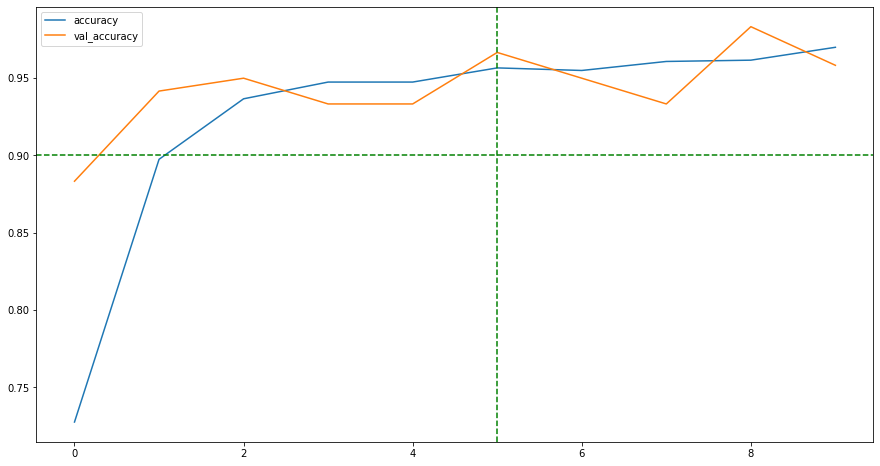
- A acurácia serve para verificarmos o quão preciso o modelo foi, quanto maior o valor, melhor.
- Como podemos ver, a medida em que as épocas aumentam, maior a acurácia fica, o é esperado de um modelo bem treinado.
Testando Novas Imagens
Para fazer o teste com uma imagem específica, estarei coletando do conjunto de validação, desde que é um conjunto que o modelo não treinou, então ele nunca 'viu' as imagens.
Para realizar esta tarefa, criei um randomizador de coleta das imagens e 2 funções:
- load_and_prep() - coleta as imagens, transforma ela em um vetor e as redimensiona para que possa ser avaliada pelo modelo.
- pred_and_plot() - passa a imagem vetorizada para o modelo, o modelo avalia a imagem dando notas de 0 a 1 para cada tipo de grão de café. O maior valor entre eles(argmax) será a classificação final do modelo, mostrando o nome do arquivo, o nome da classe que o modelo previu e uma foto do respectivo grão.
data_dir = pathlib.Path(validation_path)
class_names = np.array(sorted([item.name for item in data_dir.glob("*")])) # creating a list of class names from subdirectory
print(f'Classes are: {class_names}')
#image vectorizing function
def load_and_prep_image(filename, img_shape = 224):
img = tf.io.read_file(filename) #lendo a imagem
img = tf.image.decode_image(img) # decodificando para um formato tensor
img = tf.image.resize(img, size = [img_shape, img_shape]) # redimensionando a imagem
img = img/255. # rescale the image
return img
Classes are: ['Dark' 'Green' 'Light' 'Medium']
def pred_and_plot(model, filename, class_names):
# usando a função acima
img = load_and_prep_image(filename)
# fazendo a previsão
pred = model.predict(tf.expand_dims(img, axis=0))
# Get the predicted class
if len(pred[0]) > 1: # check for multi-class
pred_class = class_names[pred.argmax()] # pegando o maior valor da classificação
else:
pred_class = class_names[int(tf.round(pred)[0][0])] # if only one output, round
# exibindo a imagem
plt.figure(figsize=(12,8))
plt.imshow(img)
plt.title(f"ORIGINAL FILE: {filename.split('/')[-1]}\n\nMODEL PREDICTION: {pred_class}", color = 'orange', fontsize = 20)
plt.axis(False)
# selecionando um grão de café aleatório dentro do conjunto de validação.
random_folder = random.choice(os.listdir(validation_path))
# selecionando um arquivo de grão de café aleatório
random_image = random.choice(os.listdir(validation_path + '/' + random_folder + '/'))
# unindo a pasta aleatória com o arquivo aleatório
test_image = validation_path + '/' + random_folder + '/' + random_image
#print(f"Original File Path: {test_image}")
pred_and_plot(xception, test_image, class_names)

Como podemos ver, o arquivo original(medium (37).png) era um grão médio de café e a previsão do modelo foi exatamente um grão médio =D.
Por hoje é só e muito obrigado =P. críticas e feedbacks construtivos são bem vindos. Caso queira checar o código completo basta clicar aqui.